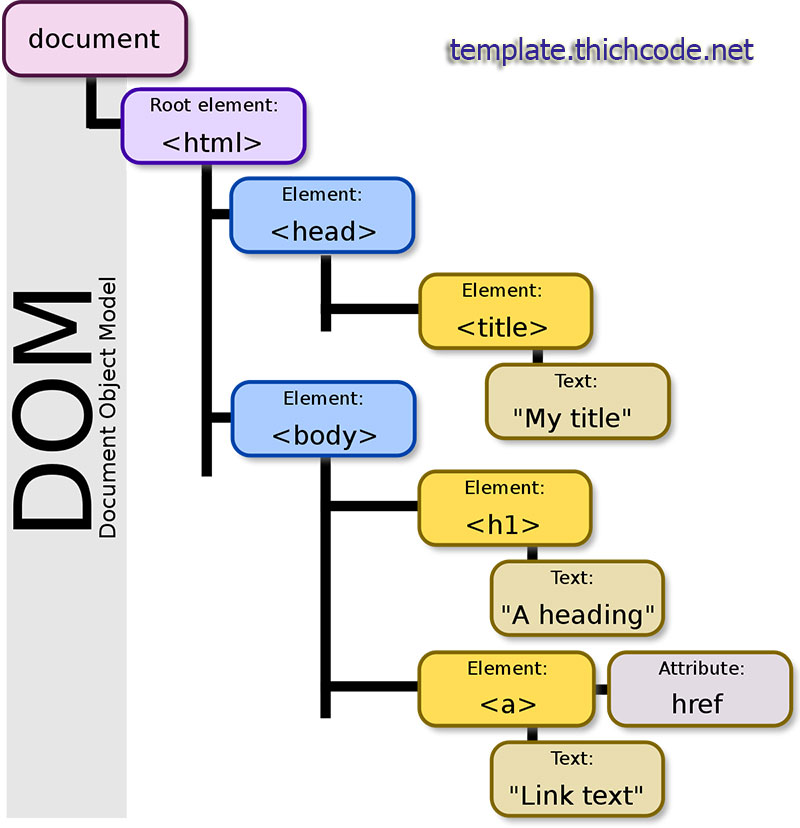
DOMDocument là một lớp trong PHP thuộc phần mở rộng DOM (Document Object Model), cung cấp các công cụ mạnh mẽ để tạo, phân tích, sửa đổi và lưu trữ tài liệu XML/HTML. Đây là một lựa chọn linh hoạt khi làm việc với nội dung dạng cây, đặc biệt là HTML và XML.
I. DOMDocument trong PHP#
1. Giới thiệu về DOMDocument#
Định nghĩa:
DOMDocumentlà một lớp cung cấp các phương thức và thuộc tính để xử lý cấu trúc DOM của tài liệu XML hoặc HTML.- DOM là một tiêu chuẩn cho việc biểu diễn và thao tác với nội dung HTML hoặc XML dưới dạng cây (tree structure).
Cách khởi tạo DOMDocument:
$dom = new DOMDocument();Các chức năng chính của DOMDocument:
- Phân tích (Parse): Đọc và phân tích nội dung HTML hoặc XML.
- Chỉnh sửa: Thêm, xóa, sửa các thành phần trong tài liệu.
- Tạo mới: Xây dựng tài liệu XML hoặc HTML từ đầu.
- Lưu trữ: Xuất tài liệu thành chuỗi hoặc tệp.
2. Các phương thức và thuộc tính quan trọng#
2.1. Tạo đối tượng DOMDocument
$dom = new DOMDocument('1.0', 'UTF-8');'1.0': Phiên bản XML.'UTF-8': Mã hóa ký tự của tài liệu.
2.2. Phân tích nội dung
loadHTML()
Dùng để phân tích (parse) nội dung HTML từ một chuỗi:
$html = "<html><body><p>Hello World</p></body></html>";
$dom->loadHTML($html);loadHTMLFile()
Dùng để phân tích nội dung HTML từ tệp:
$dom->loadHTMLFile('example.html');load()
Dùng để phân tích tài liệu XML từ tệp:
$dom->load('example.xml');loadXML()
Dùng để phân tích tài liệu XML từ chuỗi:
$xml = "<root><element>Value</element></root>";
$dom->loadXML($xml);2.3. Thao tác trên tài liệu
Tạo phần tử mới
createElement($tagName, $value = null): Tạo một phần tử với tên thẻ và giá trị nội dung.
$element = $dom->createElement('p', 'Hello World');Thêm phần tử vào tài liệu
appendChild(): Thêm một phần tử con vào tài liệu hoặc phần tử khác.
$dom->appendChild($element);Tìm kiếm phần tử
getElementsByTagName($tagName): Lấy tất cả các phần tử với tên thẻ cụ thể.
$nodes = $dom->getElementsByTagName('p');Xóa phần tử
removeChild(): Xóa một phần tử con.
$dom->removeChild($element);2.4. Xuất nội dung
saveHTML()
Xuất nội dung HTML hiện tại của DOMDocument thành chuỗi.
echo $dom->saveHTML();saveHTMLFile($fileName)
Lưu nội dung HTML vào tệp.
$dom->saveHTMLFile('output.html');saveXML()
Xuất tài liệu XML hiện tại thành chuỗi.
echo $dom->saveXML();3. Các ví dụ minh họa#
3.1. Tạo một tài liệu HTML đơn giản
<?php
$dom = new DOMDocument('1.0', 'UTF-8');
// Tạo thẻ <html> và <body>
$html = $dom->createElement('html');
$body = $dom->createElement('body');
// Tạo thẻ <p> và thêm nội dung
$p = $dom->createElement('p', 'Hello, DOMDocument!');
// Ghép các phần tử vào tài liệu
$body->appendChild($p);
$html->appendChild($body);
$dom->appendChild($html);
// Xuất tài liệu
echo $dom->saveHTML();
?>Kết quả:
<html>
<body>
<p>Hello, DOMDocument!</p>
</body>
</html>3.2. Thêm thuộc tính vào phần tử
<?php
$dom = new DOMDocument('1.0', 'UTF-8');
// Tạo thẻ <a>
$a = $dom->createElement('a', 'Click Here');
// Thêm thuộc tính href
$a->setAttribute('href', 'https://example.com');
// Thêm thẻ <a> vào tài liệu
$dom->appendChild($a);
// Xuất tài liệu
echo $dom->saveHTML();
?>Kết quả:
<a href="https://example.com">Click Here</a>3.3. Chỉnh sửa tài liệu HTML hiện có
<?php
$html = '<html><body><p>Old Text</p></body></html>';
$dom = new DOMDocument();
$dom->loadHTML($html);
// Lấy thẻ <p> đầu tiên
$p = $dom->getElementsByTagName('p')->item(0);
// Thay đổi nội dung của thẻ <p>
$p->nodeValue = 'New Text';
// Xuất tài liệu
echo $dom->saveHTML();
?>Kết quả:
<html>
<body>
<p>New Text</p>
</body>
</html>3.4. Tìm và xóa một phần tử
<?php
$html = '<html><body><p>Keep this</p><p>Remove this</p></body></html>';
$dom = new DOMDocument();
$dom->loadHTML($html);
// Lấy thẻ <p> thứ hai
$p = $dom->getElementsByTagName('p')->item(1);
// Xóa thẻ <p>
$p->parentNode->removeChild($p);
// Xuất tài liệu
echo $dom->saveHTML();
?>Kết quả:
<html>
<body>
<p>Keep this</p>
</body>
</html>4. Lưu ý khi sử dụng DOMDocument#
- Encoding: Đảm bảo sử dụng đúng mã hóa (UTF-8) khi phân tích hoặc tạo tài liệu.
- HTML không hợp lệ:
DOMDocumentcó thể phát sinh lỗi hoặc tự động sửa nội dung HTML không hợp lệ.- Sử dụng
libxml_use_internal_errors(true)để bỏ qua các lỗi.
- Sử dụng
- Thẻ tự động thêm:
DOMDocumentmặc định sẽ tự thêm thẻ<html>,<body>và<!DOCTYPE>nếu chúng không tồn tại.- Sử dụng
LIBXML_HTML_NOIMPLIEDvàLIBXML_HTML_NODEFDTDđể ngăn điều này.
- Sử dụng
5. Khi nào nên sử dụng DOMDocument?#
- Khi cần thao tác với HTML/XML dạng cây (DOM).
- Khi tài liệu phức tạp, không thể xử lý hiệu quả bằng các công cụ đơn giản như
str_replacehoặcpreg_replace. - Khi cần đảm bảo tính toàn vẹn và chuẩn của tài liệu HTML/XML.
II. Ví dụ thêm thẻ <a> cho thẻ <img>#
Để tìm tất cả hình ảnh trong nội dung HTML, sau đó chèn chúng vào thẻ<a> với các thuộc tính như yêu cầu, bạn có thể sử dụng PHP kết hợp với regular expressions (regex) hoặc DOMDocument để xử lý nội dung HTML. Dưới đây là cách thực hiện:
Giải pháp 1: Sử dụng DOMDocument#
Đây là cách làm an toàn và hiệu quả nhất khi xử lý nội dung HTML.
<?php
// Nội dung HTML đầu vào
$htmlContent = '
<p>Đây là nội dung có hình ảnh.</p>
<img src="image1.jpg" alt="Hình ảnh 1">
<img src="image2.png" alt="Hình ảnh 2">
';
// Tạo đối tượng DOMDocument
$dom = new DOMDocument();
libxml_use_internal_errors(true); // Bỏ qua lỗi HTML không hợp lệ
$dom->loadHTML(mb_convert_encoding($htmlContent, 'HTML-ENTITIES', 'UTF-8'), LIBXML_HTML_NOIMPLIED | LIBXML_HTML_NODEFDTD);
libxml_clear_errors();
// Lấy tất cả thẻ img
$images = $dom->getElementsByTagName('img');
// Lặp qua các thẻ img và bọc chúng trong thẻ <a>
foreach ($images as $image) {
$src = $image->getAttribute('src'); // Đường dẫn hình ảnh
$alt = $image->getAttribute('alt'); // Alt text (hoặc title)
// Tạo thẻ <a>
$link = $dom->createElement('a');
$link->setAttribute('href', $src);
$link->setAttribute('data-lightbox', 'thumb');
$link->setAttribute('data-title', $alt);
// Sao chép thẻ img vào bên trong thẻ <a>
$link->appendChild($image->cloneNode(true));
// Thay thế thẻ img cũ bằng thẻ <a> mới
$image->parentNode->replaceChild($link, $image);
}
// Xuất HTML kết quả
echo $dom->saveHTML();Giải pháp 2: Sử dụng Regex#
Regex có thể xử lý nhanh hơn, nhưng kém chính xác nếu nội dung HTML phức tạp.<?php
// Nội dung HTML đầu vào
$htmlContent = '
<p>Đây là nội dung có hình ảnh.</p>
<img src="image1.jpg" alt="Hình ảnh 1">
<img src="image2.png" alt="Hình ảnh 2">
';
// Regex để tìm thẻ <img>
$pattern = '/<img\s+([^>]*?)src=["\']([^"\']+)["\']([^>]*?)>/i';
// Thay thế thẻ <img> bằng thẻ <a> chứa thẻ <img>
$result = preg_replace_callback($pattern, function ($matches) {
$src = $matches[2];
$alt = '';
if (preg_match('/alt=["\']([^"\']+)["\']/', $matches[1] . $matches[3], $altMatch)) {
$alt = $altMatch[1];
}
return '<a href="' . $src . '" data-lightbox="thumb" data-title="' . htmlspecialchars($alt) . '">'
. $matches[0] . '</a>';
}, $htmlContent);
// Xuất HTML kết quả
echo $result;Kết quả đầu ra#
Với nội dung đầu vào:<p>Đây là nội dung có hình ảnh.</p>
<img src="image1.jpg" alt="Hình ảnh 1">
<img src="image2.png" alt="Hình ảnh 2"><p>Đây là nội dung có hình ảnh.</p>
<a href="image1.jpg" data-lightbox="thumb" data-title="Hình ảnh 1">
<img src="image1.jpg" alt="Hình ảnh 1">
</a>
<a href="image2.png" data-lightbox="thumb" data-title="Hình ảnh 2">
<img src="image2.png" alt="Hình ảnh 2">
</a>Chọn phương pháp nào?#
- Dùng
DOMDocument: Khi bạn làm việc với nội dung HTML phức tạp hoặc cần độ chính xác cao. - Dùng Regex: Khi nội dung đơn giản và bạn cần xử lý nhanh.
III. Mở rộng thêm về DOMDocument()#
Giải thích chi tiết đoạn code ở ví dụ trên#
$dom->loadHTML(mb_convert_encoding($htmlContent, 'HTML-ENTITIES', 'UTF-8'), LIBXML_HTML_NOIMPLIED | LIBXML_HTML_NODEFDTD);1. $dom->loadHTML($htmlContent, ...)
$dom: Là một đối tượng thuộc lớpDOMDocument, được sử dụng để tạo hoặc chỉnh sửa nội dung XML/HTML.loadHTML(): Là một phương thức củaDOMDocument, được sử dụng để phân tích (parse) và tải nội dung HTML vào đối tượngDOMDocument.mb_convert_encoding($htmlContent, 'HTML-ENTITIES', 'UTF-8'): chuyển nội dung sang UTF-8
2. $htmlContent
- Chuỗi chứa nội dung HTML cần được phân tích và xử lý.
3. LIBXML_HTML_NOIMPLIED
- Đây là một hằng số thuộc thư viện
libxml, có tác dụng vô hiệu hóa việc tự động thêm các thẻ<html>và<body>vào nội dung HTML khi sử dụngloadHTML(). - Mặc định, nếu HTML không có các thẻ
<html>hoặc<body>,DOMDocumentsẽ tự động thêm chúng vào. Hằng số này ngăn điều đó xảy ra.
- HTML gốc:
<p>Hello</p> - Mặc định (không có
LIBXML_HTML_NOIMPLIED):<html> <body> <p>Hello</p> </body> </html> - Có
LIBXML_HTML_NOIMPLIED:<p>Hello</p>
4. LIBXML_HTML_NODEFDTD
- Ngăn
DOMDocumenttự động thêm doctype (Document Type Definition) vào nội dung HTML. - Mặc định, nếu không có
LIBXML_HTML_NODEFDTD,DOMDocumentsẽ thêm dòng<!DOCTYPE html>vào đầu nội dung.
- HTML gốc:
<p>Hello</p> - Mặc định (không có
LIBXML_HTML_NODEFDTD):<!DOCTYPE html> <html> <body> <p>Hello</p> </body> </html> - Có
LIBXML_HTML_NODEFDTD:<html> <body> <p>Hello</p> </body> </html>
Các hằng số liên quan đến loadHTML#
loadHTML sử dụng các hằng số từ thư viện libxml để điều chỉnh hành vi xử lý nội dung HTML. Dưới đây là một số hằng số phổ biến:
1. LIBXML_NOERROR
- Bỏ qua các lỗi không nghiêm trọng khi phân tích HTML.
- Giúp xử lý các HTML không hợp lệ hoặc bị lỗi mà không tạo ra thông báo lỗi.
2. LIBXML_NOWARNING
- Bỏ qua các cảnh báo khi phân tích HTML.
- Sử dụng khi bạn không muốn hiển thị thông báo cảnh báo trong quá trình phân tích.
3. LIBXML_HTML_NOIMPLIED
- Đã giải thích ở trên: Ngăn việc tự động thêm thẻ
<html>và<body>.
4. LIBXML_HTML_NODEFDTD
- Đã giải thích ở trên: Ngăn việc tự động thêm
<!DOCTYPE html>.
5. LIBXML_COMPACT
- Giảm tiêu thụ bộ nhớ khi xử lý các tài liệu lớn.
6. LIBXML_PARSEHUGE
- Cho phép phân tích các tài liệu HTML rất lớn, vượt quá giới hạn mặc định của
libxml.
Khi nào nên sử dụng các hằng số này?#
LIBXML_HTML_NOIMPLIED: Khi bạn muốn giữ nguyên cấu trúc HTML, đặc biệt khi chỉ làm việc với một phần của tài liệu (ví dụ: một đoạn<div>hoặc<p>).LIBXML_HTML_NODEFDTD: Khi không cần thêm<!DOCTYPE html>, thường áp dụng khi xử lý các đoạn HTML nhúng hoặc không phải tài liệu hoàn chỉnh.LIBXML_NOERRORvàLIBXML_NOWARNING: Khi bạn làm việc với HTML không hợp lệ hoặc thiếu chuẩn, và không muốn thông báo lỗi làm gián đoạn.LIBXML_COMPACTvàLIBXML_PARSEHUGE: Khi làm việc với các tệp HTML lớn hoặc tài liệu phức tạp.
Ví dụ sử dụng hằng số#
$html = '<p>Hello World</p>';
// Tạo DOMDocument
$dom = new DOMDocument('1.0', 'UTF-8');
// Bỏ qua lỗi và không thêm thẻ tự động
libxml_use_internal_errors(true);
$dom->loadHTML($html, LIBXML_HTML_NOIMPLIED | LIBXML_HTML_NODEFDTD);
libxml_clear_errors();
// In nội dung sau khi xử lý
echo $dom->saveHTML();<p>Hello World</p>Nội dung bài viết
- I. DOMDocument trong PHP
- 1. Giới thiệu về DOMDocument
- 2. Các phương thức và thuộc tính quan trọng
- 3. Các ví dụ minh họa
- 4. Lưu ý khi sử dụng DOMDocument
- 5. Khi nào nên sử dụng DOMDocument?
- II. Ví dụ thêm thẻ <a> cho thẻ <img>
- Giải pháp 1: Sử dụng
DOMDocument - Giải pháp 2: Sử dụng Regex
- Kết quả đầu ra
- Chọn phương pháp nào?
- III. Mở rộng thêm về DOMDocument()
- Giải thích chi tiết đoạn code ở ví dụ trên
- Các hằng số liên quan đến
loadHTML - Khi nào nên sử dụng các hằng số này?
- Ví dụ sử dụng hằng số